|
The Quantum Age of Information
|
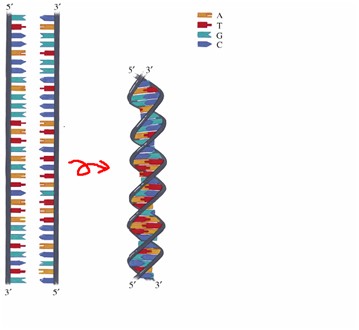
The weird quantum mechanical effects governing the behavior of sub-atomic particles are about to revolutionize the way we perform computations and manipulate information. Genuine quantum mechanical properties, like superposition of states, entanglement and interference, can be harnessed in order to speed up computation or enhance the security of data communications. Quantum parallelism exploits the ability of a qubit to encode superpositions of the classical states 0 and 1 (see Fig. 1), thus allowing a function to be evaluated for all possible inputs simultaneously (see Figures 2 and 3). This feature enables some quantum algorithms to gain an exponential speed-up over their best classical counterparts. The most notable example is Peter Shor's algorithm for factoring integers in quantum polynomial time, a problem considered intractable for a conventional computer.
But the fundamental ability of a quantum computer to process information at a deeper physical level than a conventional computer is able to, allows the former to tackle a much broader palette of information processing tasks, thus establishing its superiority in terms of computational power. Specifically, we have uncovered a class of information processing tasks (based on the problem of
distinguishing among entangled quantum states) whose members are readily carried out by a quantum computer, yet are impossible to perform on any classical machine, whether deterministic or probabilistic.
Quantum cryptographic protocols take advantage of other laws of quantum mechanics, like Heisenberg's uncertainty principle and the impossibility of cloning unknown quantum bits in order to design cryptographic schemes that are able to detect potential eavesdroppers. The information in transit is usually encoded in the polarization states of photons (see Figure 4).
Taking advantage of quantum memories, we have shown how entanglement-based protocols can use more efficient schemes to detect whether a pair of entangled qubits was tampered with while en route to the legitimate parties. For those quantum key distribution protocols not based on any form of entanglement, we have proposed the first protocol capable of propagating the disruption caused by eavesdropping to quantum bits that were not disturbed while in transit. In order to achieve this, we used the quantum Fourier transform to propagate the disruption caused by eavesdropping on one qubit to other qubits in the sequence. This is very important especially for low levels of eavesdropping, where partial knowledge about the sequence transmitted is considered better than nothing.
Our research has also tackled the important problem of authentication in communications and we showed for the first time that quantum key distribution protocols can also provide authentication, based only on public information. Also, our work in ensuring the security of information transmitted in a network has the potential to apply to important emerging areas, like sensor networks.
We have also demonstrated the importance of parallelism for quantum computation and quantum information by providing several examples of tasks for which a parallel approach can make the difference between success and failure. The common property of these tasks is their dynamic nature. Their characteristics change during the computational process itself, for which reason they are often labeled as unconventional. The study of parallelism in unconventional computing environments leads to the conclusion that a Universal Computer with fixed and finite physical characteristics cannot exist.
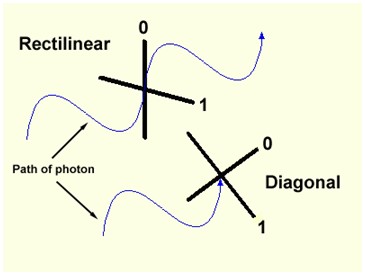
Figure 4
|
|
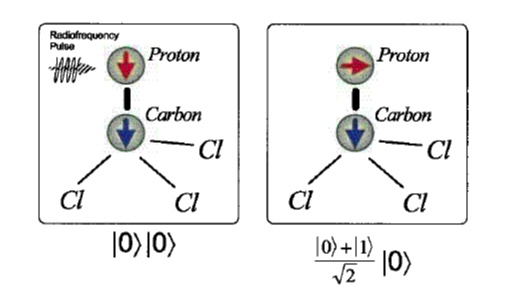
Figure 1
|
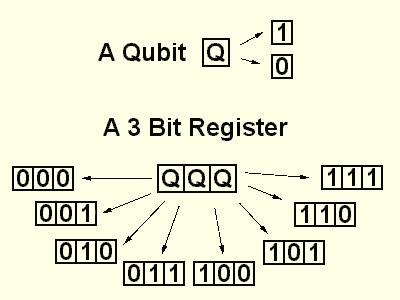
Figure 2
|
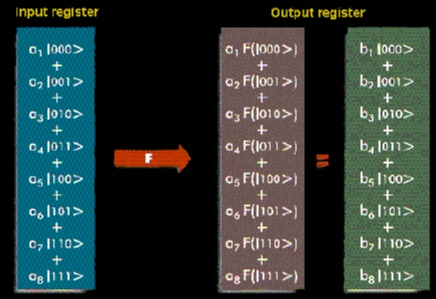
Figure 3
|
|
|
Project Members:
Dr. Selim Akl, Dr. Marius Nagy, and Naya Nagy.
|
|
|
The Biological Age of Information
|
Virtually all computers we currently use are based on semiconductor technology. Silicon semiconductors perform all computations in industry today. Although silicon based computers improve rapidly, computational needs also increase, as ever more complex problems can be formulated and wait to be solved. Searching for more powerful computers, opens the door to researching utterly different technologies, miniaturized to even elemental components (such as molecules or atoms). These are expected to challenge the limits of current semiconductor technology.
Many existing physical and chemical systems in our natural environment are surprising by their highly organized structure. None of them, however, can compete with the simplest biological system. Any biosystem excels in terms of its complexity, its design, the processes it performs, its adaptability to changing circumstances, and so on. A colony of bacteria, a cell, or a cell complex can be viewed and studied as micro scale living in vivo biological systems. Subsequently, any chain of interdependent biochemical processes affecting synthesized organic molecules also forms a biological system in vitro. In the latter case, organic molecules refer to molecules of DNA, RNA, proteins, enzymes, and so on, which are not alive themselves but play an active, indeed crucial, role in the life of a cell or body. For example, a set of DNA strands in a water solution undergo transformations of lengthening, shortening, annealing, multiplication, and filtering. This yields a well defined in vitro biological system.
The idea follows immediately: Could a biological system (a collection of cells) work at a task defined by a human? Living organisms already accomplish vastly complex tasks in nature, and do so reliably.
The goal of Biological Computing is exactly this: To solve computational problems using a biological system rather than a conventional computer. When a biosystem yields the �hardware", aptly named �bioware" a new biocomputer is born.
Biological Computing is generally divided into three branches, namely, DNA computing, membrane computing and gene assembly in ciliates.
In DNA computing the computation is performed by DNA strands. DNA molecules undergo lab manipulations, the equivalent of computational steps. The result of a computation is read from the linear structure of the final DNA strand.
In membrane computing, a biological system of membranes act as a computer. The field deals with abstractions of the membrane structure. No practical implementations have been achieved, nor is there anything in site.
Gene assembly in ciliates studies the formation of genes in ciliates. This natural process is able to unscramble any permutation of the gene, and as such shows computational potential.
|
|
|
|
Project Members:
Dr. Selim Akl and Naya Nagy.
|
|
|
Wireless Sensor Networks
|
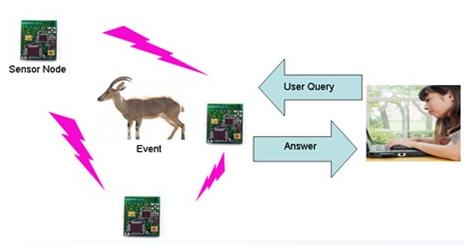
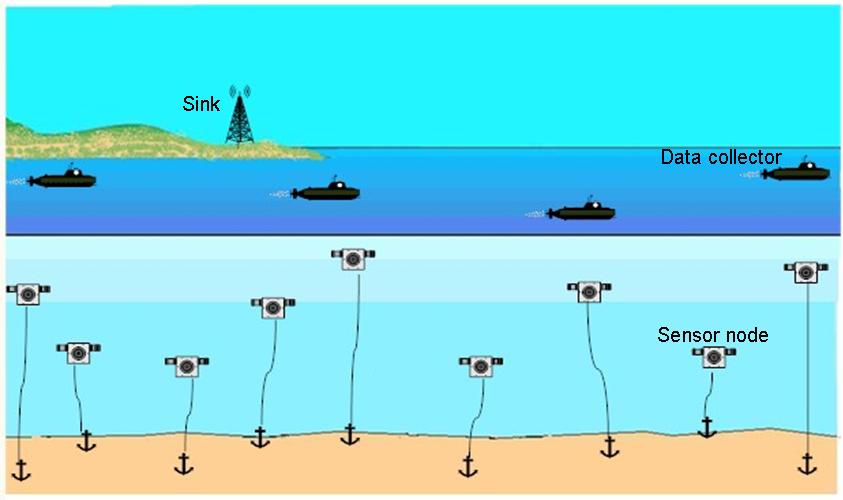
Advances in wireless communication and embedded microprocessors have brought about the development of small, low-cost sensor nodes, which are able to collect data from the surrounding environment and to communicate in short distances. They report the data they collect to a central node, called the sink, using a wireless medium. These tiny devices are battery-operated and, hence, untethered in terms of both power and communication. This enabled a new generation of large-scale networks of untethered, unattended sensor nodes suitable for a wide range of commercial, scientific, health, surveillance, and military applications. This rapidly evolving technology has the potential to revolutionize the way we interact with the physical environment and to facilitate collecting data which have never been available before. However, as a result of the limited energy supply for sensor nodes, extending the network lifetime has become crucial for Wireless Sensor Networks (WSNs) to deliver their promises; and that is the focus of our research.
Underwater WSNs
Underwater WSNs have prominent potential for environmental monitoring and oceanographic data gathering. Most of the work in underwater sensing and data collection is based on wired networks, which demand high cost and significant engineering effort. Recently, attention has been directed to acoustic networks as they are able to provide low-cost, distributed underwater monitoring. One of the problems in underwater WSNs is the bottlenecks near the sink; because of multi-hop relaying, nodes around the sink relay data generated all over the network to the sink and deplete their energy much faster than other nodes. To solve this problem, we propose the use of multiple mobile data collectors.
We consider a system of N sensor nodes and R data collectors. Each sensor node collects data from the surrounding environment and sends the collected data to one of the collectors either directly (if possible) or through other nodes (i.e., multi-hop relaying). We consider a three-dimensional architecture, in which data collectors are equipped with a radio transceiver to communicate with an on-shore sink, and an acoustic transceiver to communicate with underwater sensors. While data collectors stay on the surface to keep the link with the sink, sensor nodes, which are equipped with acoustic transceivers, float at different depths to carry out the sensing mission. Routing and mobility of data collectors need to be managed carefully in order to balance the load over different parts of the network and, hence, prolong the network lifetime.
|
|
|
Project Members:
Professors: Dr. Selim Akl and Dr. Hossam Hassanein. Students: Waleed Alsalih, Francisco De la Parra, Kamrul Islam, and Naya Nagy.
|
|
|
Grid Computing
|
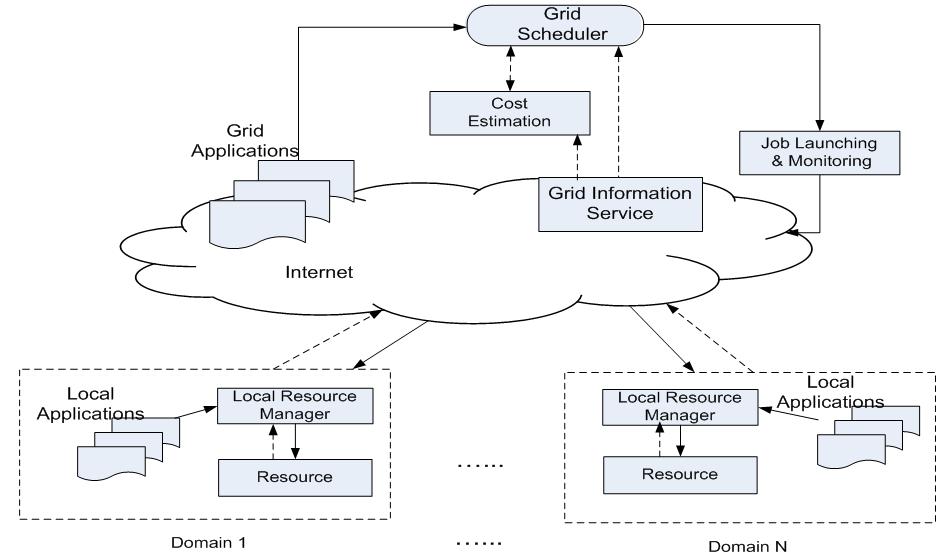
Grid Computing is a computational paradigm that utilizes geographic distributed computational resources by some standard, open, general-purpose protocols and interfaces, to provide nontrivial qualities of service to its users.
The emergence of Grid Computing was motivated by two factors: the increasing demand for high performance computation resources from various applications (e.g., DNA analysis, high energy physics, and long term weather forecast), and the wide deployment of Internet that makes it possible to remotely visit computational sites, data storage, and instruments.
What are we doing in our lab?
To achieve the promising potentials of tremendous distributed resources in the Grid, effective and efficient job scheduling algorithms are fundamentally important. Unfortunately, job scheduling algorithms in traditional parallel and distributed systems, which usually consist of homogeneous and dedicated resources, cannot work well in the new Grid Computing circumstances. Being aware of this new challenge, we are designing and evaluating new scheduling algorithms for workflow applications in the Grid environment, which include: Scheduling algorithms adaptive to the Grid architecture Scheduling algorithms adaptive to resource performance fluctuation Scheduling algorithms synthesizing computational tasks and data transmission Scheduling algorithms considering Quality of Service requirements of applications.
|
|
|
|
Project Members:
Dr. Selim Akl and Fangpeng Dong
|
|