The following list contains the four things that we need to be able to implement procedures and functions:
Transferring control to a subroutine and then returning from it involves changing the value of the program counter, so special instructions that modify the PC are involved. On the Pep/6, they are JSR, for Jump to Subroutine, and RTS, for Return from Subroutine. The two instructions use the run-time (user) stack to save the address to return to.
Stacks provide a Push(item) operation which adds item to the top of the stack, and a Pop() operation which removes the top item from the stack and returns it to the caller.
You can implement a stack with an array of whatever data type you are stacking up, and an index to the element currently at the top of the array. Here's a rudimentary Java implementation of a stack of integers. In object-oriented style this would probably be packaged up as a class; but for our purposes it will just be a set of static methods. (This set of methods make no attempt to indicate stack over or underflow. In software practice, it would be good design to indicate the success/failure status of each operation. This could be done by settting another variable (static boolean stackError), or (in Java) by throwing an exception. However, in hardware on many machines there is no indication that the stack has overflowed until a program starts trying to store values into non-stack memory, which can cause anything to happen including crashing the whole system. This was a notorious problem with early personal computers.)
// Simple integer stack using static variables. This stack grows down, toward
// lower index numbers, just as the Pep/6 run-time stack grows toward lower addresses.
// Overflow and underflow operations are ignored.
static final short maxIndex = 9;
short stack [maxIndex];
short top = maxIndex + 1; // Initialized to value indicating empty stack.
// Add 'item' to the top of the stack, if there is room.
static void push (short item)
{
if (top > 0)
stack [--top] = item;
} // push
// Remove and return the value on the top of the stack, if any.
short pop ()
{
if (top <= maxIndex)
top = top + 1;
return (stack [top-1]);
}
void stackUser ()
{
short i;
for (i = 1; i <= 10; i++)
push (i);
for (i = 1; i <= 10; i++)
Io. decimalOutput (pop ());
}
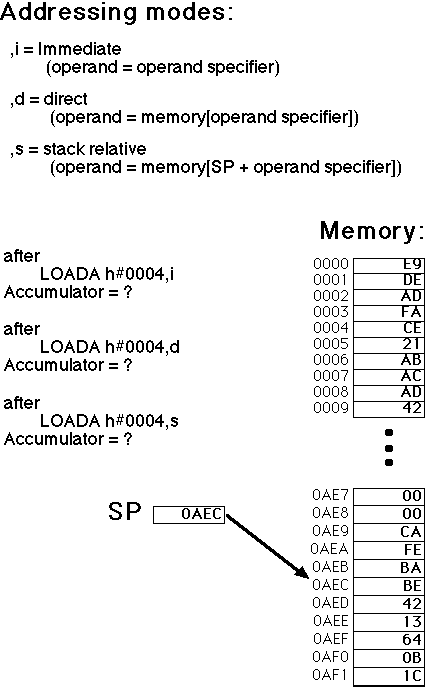
You'll remember from the Pep/6 operating system's memory map that it has
two run-time stacks which are used to implement procedures. The Pep/6 uses
these sections of memory for storing the contents of the stack, and the
stack pointer register, SP, to contain the address of the byte
which is currently at the top of the stack.
The main and somewhat confusing difference between a usual stack implementation and stacks used in Pep/6 is the fact that the stack in Pep/6 grow backwards (i.e. to the top of the memory) and therefore when we push an item onto the stack we need to decrement the SP and when we pop an item from a stack we need to increment it.
the CPU performs the steps:JSR addressOfSubroutine
The first two steps push the return address onto the stack, and the third transfers control to the subroutine. The stack pointer is decremented by two because the address being pushed onto the stack occupies two bytes.SP := SP - 2 Mem[SP] := PC PC := addressOfSubroutine
To execute instruction:
the PC performs the stepsRTS
These steps pop the return address off the run-time stack and load it into the PC, transferring control back to the instruction after the subroutine call.PC := Mem[SP] SP := SP + 2
Why couldn't we store the return address into a special register, instead of putting it on the stack? Think about what would happen when the body of one procedure included a call to another procedure.1
Using the JSR and RTS instructions, we could implement the program with a subroutine, but there would be a problem still with parameters, local variables and return value.
If each of these variables has been allocated "static memory" (static because the variables remain at the same address in memory for the entire life of the program) then no implementation of recursive calls can happen and also more memory space is needed for a program than the program actually requires. (This is because, for example, the space used for local variables can be reused for the another subroutine's local variables).
Up to now, we've seen
------------------------------------------------------------------------------- Object Addr code Mnemon Operand Comment ------------------------------------------------------------------------------- ; ; Assembly language program that pushes onto stack ; 4 characters 'onof' and pops from the stack also 4 ; characters but in a different order creating output ; 'noon' and then deallocate (pops) those 4 characters ; 0000 08006F LOADA c#/o/,i 0003 5AFFFF STBYTA d#-1,s 0006 08006E LOADA c#/n/,i 0009 5AFFFE STBYTA d#-2,s 000C 08006F LOADA c#/o/,i 000F 5AFFFD STBYTA d#-3,s 0012 080066 LOADA c#/f/,i 0015 5AFFFC STBYTA d#-4,s ; 0018 68FFFC ADDSP d#-4,i ; push the 4 characters ; and now the same characters ; have a different stack ; pointer relative address ; 001B E20002 CHARO d#2,s ; print "n" 001E E20001 CHARO d#1,s ; print "o" 0021 E20003 CHARO d#3,s ; print "o" 0024 E20002 CHARO d#2,s ; print "n" 0027 680004 ADDSP d#4,i ; pop the 4 characters ; 002A 00 STOP ; 002B .END ------------------------------------------------------------------------------- No errors. Successful assembly.
The MIPS still has a run-time stack, though, and the code implementing the body of the subroutine has the responsibility of saving the value in $ra onto that stack should it make a call to another subroutine itself. The rationale for having the program code explicitly manipulate the stack, rather than having the hardware always do so automatically, is that doing so allows "leaf subroutines" (subroutines that don't call any other subroutines) to avoid the memory accesses involved in manipulating the stack.