Quilt: Design for the Software Carpentry Contest build Category
Quilt is a tool I have designed, on and off, for the last 15
years or so. This version is a submission to the Software Carpentry contest,
in the SC build category. Due to my prolonged illness this entry is
incomplete, but I am submitting in hope that there is enough content to show
the judges what I had planned to do.
Much of the content is revisions of earlier papers, cited in the references. My tools (wc of a lynx
-dump) say this is just under 4420 words long.
This document is Copyright 2000 David Alex Lamb, and is available under the
Software Carpentry Open
Publication Licence
| Name
| David Alex Lamb
|
|---|
| Address
| Department of Computing and Information Science
Goodwin Hall
Queen's University
Kingston, Ontario, CANADA K7L 3N6
|
|---|
| E-mail
| http://www.cs.queensu.ca/~dalamb/
|
|---|
The requirements phase of this project consists of
identifying the original requirements stated at the
Software Carpentry site;
identifying my own personal additional requirements,
and developiong a conceptual model of the long-term
data the tool must manage.
The original requirements for this project come from the Software Carpentry SC Build
contest category.
- Suitable replacement for UNIX
make, with features such as:
- building programs in a variety of languages,
- running arbitrary commands for reporting purposes,
- rebuilding documentation
- Managing and representing dependencies (item 1)
- Handling options in compilation (item 2)
- Handling complex directory structures, such as separate build and source
trees (item 4)
- Using techniques other than timestamps (item 6)
- Inspecting a complex build, e.g. graphical dependency display (item 11)
- Keeping track of artifacts it has produced, e.g. for cleanup (item 13)
- Feedback on the progress of the build (item 10)
- Management of tools used during the build:
- tracking changes in tools, especially those used to discover
dependencies(item 15);
- coping with errors (part of item 12);
- missing tools (item 16)
My previous work has involved systems with the following characteristics:
- A system is composed of several subsystems, each of which may have its
own substructure.
Each subsystem might be reusable, and thus might be part
of several distinct systems.
- Subsystems evolve; each subsystem might be under the control of a separate
project, and might have its own independent development schedule. The manager
of a project using subsystems can choose the version of a subsystem to use,
but beyond that cannot control the contents of a subsystem.
- Each subsystem consists of exported (visible) components,
plus internal components. Components might be programming
language modules, or tools, or data files. Other subsystems might know
the visible components, but should be able to ignore the hidden
components. However, system-wide processing tools, such as the linker,
need to know all the components, or perhaps all components with certain
properties, of all subsystems.
- Source components are not all written in the same language. This
property comes not so much from mixing ordinary programming languages
as from having tools that generate portions of the system. The input
notation for each tool is a different language. Furthermore, there may
be long chains of tools generating output that becomes the input to yet
other tools.
These experiences have let to my personal goals for this project:
- Make reasonable use of
Ellen Borison's model of software manufacture and
my previous related work on
abstractions and relations.
- Provide a flexible mechanism for describing build steps,
separating inputs into explicit (e.g. a file to compile) and
implicit (e.g. the
#include files.
- Cope with complex projects where portions of a system are under the
control of separate groups, e.g. separate "front end" and "back end"
and "tools" teams for a compiler-building project.
- Allow for, but do not require, interaction between the build process and
other tools. For example, a language processor might produce a list of
direct dependencies it discovers, and ask the build processor to record
them (so that in future they're done first).
The following sections show several specific problems that occur in this kind
of system.
Consider the following example,
which shows a
make
input file for a small system consisting of a main program and two
submodules.
This example ignores
make's
mechanisms for specifying
default rules,
which could shorten the example somewhat, but do not solve the problems
we address here.
CCFLAG=-c -g
prog: main.o mod1.o mod2.o mod3.o
ld -o prog main.o mod1.o mod2.o mod3.o
main.o: main.c mod1.h mod2.h
cc ${CCFLAG} main.c
mod1.o: mod1.c mod1.h mod3.h
cc ${CCFLAG} mod1.c
mod2.o: mod2.c mod2.h mod3.h
cc ${CCFLAG} -DLISTOPTION=short mod1.c
mod3.o: mod3.c mod3.h
cc ${CCFLAG} -DDEBUG mod1.c
Each line that starts in the left margin says that the target file, whose name
precedes the colon (:), depends on all those files whose names follow the
colon; if any of them change,
make
must use the immediately following command to rebuild the target.
The dependency of
prog
on
main.o
arises because
main.o
is a relocatable file we pass to the linker to make up the
executable program.
The dependency of
main.o
on
main.c
arises because
main.c
is the source file from which we get the relocatable file
main.o;
the dependencies on
mod1.h
and
mod2.h
arise because
main.c
incorporates these two files by file inclusion.
However, there are several more hidden dependencies.
-
mod3.o
also depends on the command line arguments
"${CCFLAG} -DDEBUG";
if we change these options, we must recompile
mod3.o,
but
make
does not detect this.
The fourth generation
make
program
lets a file depend on the contents of macros;
by putting each distinct set of command line options in a macro we
can record these dependencies, but this is clumsy for a system designer
to do.
-
The linking step implicitly depends on the C library, usually a particular file.
This may not seem important in a system where such files rarely change;
however, in some environments (such as those using a compiler and library
that themselves are under development) such hidden files can change rapidly.
Furthermore, if we had this information we could use it to find all the files
we would need to archive to tape to be able to faithfully rebuild an
old version of the system.
-
All the C compilations depend on the C compiler. However, the compiler itself
runs several other programs, such as the C preprocessor. Furthermore, what
C compiler we get depends on the value of the search path variable (PATH)
in the shell; in an environment with several possible versions of a tool,
such considerations become important.
Even if we could in principle record all these dependencies, forcing a
system designer to specify the full manufacture graph in such detail would
cause enormous headaches.
Adding independent subsystems causes even more problems, since now portions of
the manufacture graph for a system would be under the control of the
developers of different subsystems.
Anyone who does much complex software manufacture eventually develops
a collection of idioms she uses over again. Such idioms are patterns of
multi-step manufacture subprocesses; they have several characteristics:
- They are reusable in the same system, or different systems.
- They produce several objects.
- The builder might want to selectively reconstruct individual objects,
rather than all the objects in the subprocess.
- There should be a way to hide some of the intermediate objects in the
subprocess;
their existence should not really be visible outside the subprocess.
make
has no abstraction mechanism that can express such idioms; the only way
to capture them is to use tools such as the
sed
stream editor to generate portions of a
make
input file.
For example, the following figure
shows the process I used to produce individual chapters of a Software
Engineering textbook.

The
&
symbol stands for the name of a chapter. The
&
object is the main exported result;
it involves first making the printable form of the chapter
(&.hp),
then postprocessing some auxiliary outputs to update global book-wide
data files. The
&.chk
object involves building three different objects (&.spl,
&.styl,
&.dic),
which contain reports from simple machine proofreading
programs; you might want to select each of them independently.
Some objects serve as intermediate processing points; for example,
&.de
is the result of filtering out text formatter markup that would confuse the
proofreading programs; it is input to two of the proofreaders.
We can look to standard ideas from programming language design to solve these
problems. Given any language semantic unit X, such as a manufacture step,
we can introduce the idea of an X-valued abstraction.
Thus the input language for a manufacture tool should allow
parameterized abstractions.
The parameters would be objects (such as files or strings).
Thus, for example, I might invoke a Chapter abstraction as:
intro: chapter(intro.n)
An abstraction would act somewhat like a generic module (Ada) or template
class (C++).
After you invoke such an abstraction, you could reference individual
exported components (such as
intro.use,
or
intro.hp).
You could independently build any exported component.
The manufacture tool might support a library mechanisms for such abstractions,
so you could reuse them.
One sign that an idea is a good one is for it to elegantly solve
problems other than the ones you planned for. The
serendipity with abstractions is that the
same mechanism works for subsystem descriptions; a subsystem might be just
an abstraction that you invoke only once per system.
make
has difficulty handling transitive dependencies.
For example, consider the C source file
x.c,
which incorporates several
.h
files by file inclusion:
x.o: x.c x.h lib1.h lib2.h lib3.h
cc $(CCFLAG) x.c
Now suppose we are trying to simulate abstract data types in C.
Module
lib1
might define some type with some fields intended to be visible to its clients,
and others intended to be hidden. Suppose we add some
"hidden"
fields, and so modify
lib1.h
to include
adt1.h.
Unfortunately, we cannot really hide such fields in C, even though we know we
will not reference them in clients of
lib1;
we must recompile
x.c
whenever
adt1.h
changes, since the sizes of some records defined in
lib1.h
might change.
Existing approaches have problems.
- We could make
x.o depend on adt1.h. However,
we must do this for all the clients of lib1; this is a
repetitious, error-prone editing job.
- We could add the step:
lib1.h: adt1.h
touch lib1.h
to the manufacture graph. When adt1.h changes, this
forces lib1.h to change, too. However, this fails if
lib1.h is part of a reusable subsystem, since clients of
the subsystem would typically not have permission to modify the
date-of-last-change of such files. Furthermore, because of
cross-subsystem dependencies, adt1.h and
lib1.h might be in separate subsystems; two different
clients of the same version of lib1.h might sensibly
select different versions of adt1.h. Finally, even
without these problems, your environment may have other uses for
accurate modification dates that this mechanism would defeat.
- We could cause our manufacture tool to scan source files automatically
for inclusion directives, and deduce dependencies from them.
In some environments this is a good solution.
However, this requires a (potentially) language-specific scanning tool
for each language in our toolset.
Furthermore, in some commercial software environments, this approach
places too much control of the system structure in the wrong place;
managers may want a "freezable"
description of the system interdependencies, rather than distributing
this information throughout the source code. It would be better to
find an approach that would allow us to specify such dependencies by
hand when we had to, but allow tools to help when we have time to build
them.
I believe the best approach is to separate out different kinds of
dependencies. Thus x.o has a clear-cut direct dependency on
x.c; however, depending on x.c implies a dependency
on lib1.h and so on; depending on lib1.h implies a
dependency on adt1.h. We can construct a database of such
implied dependencies. If x depends directly on y, and y implies a
dependency on z, then changing z means rebuilding x, without rebuilding y.
We can build such a database by hand if we have no appropriate tools.
When we can afford to schedule the effort to build one, a
database editor can invoke language-specific scanners to find or check
such dependencies when asked to do so.
Suppose source file
mod.c
depends directly on
lib1.h.
Normally,
lib1.h
is the specification part of a module whose implementation is in
lib1.o.
This means that
mod.o
implies a dependency on
lib1.o;
that is, any system that includes
mod.o
must also include
lib1.o.
Current systems manage this problem in one of two ways, both of which have
some difficulties.
- The system builder might
explicitly list all relocatable object files for the linker.
This is a tedious and error-prone process if done manually.
- The system builder might instruct the manufacture tool to place all
such relocatable object files in a linker library, and
rely on the library external symbol resolution rules to link in all
appropriate components.
The second solution can work if each separate project using
several subsystems can afford the space for a library file large enough
to hold copies of all the object files of all the subsystems, and if the
linker can correctly resolve backward references in such a library.
However, many projects cannot afford the space for so many copies; instead,
they expect to have separate libraries for each subsystem, shared among all
the users of a subsystem.
Furthermore, many linkers are not clever enough for such a search strategy;
they may
expect new object modules to refer only to previously-linked symbols, or
to symbols that will appear in later object modules. Even if they do allow
arbitrary references within a library file, they may not allow it across
a list of library files; thus, projects that cannot afford so many
copies of object modules are out of luck if there are any loops in
the relationships among subsystems.
A related problem for systems that must explicitly list what object modules to
link is subset management. Suppose
a subsystem exports k modules, each of which depends on different
subsets of its hidden modules.
Different clients might import different subsets of the exported modules.
The problem is that there are potentially 2k-1 distinct collections
to manage.
A possible direction for a solution is to develop a mechanism for the
process of constructing
mod.o
from
mod.c
to generate an implied dependency of
mod.o
on
lib1.o;
we call this a
derived dependency.
The manufacture step for constructing the executable program would
specify only a direct dependency on
main.o,
the object file for the main program.
The manufacture tool could deduce all the rest of the object files from
implied and derived dependencies.
Indeed, the simplicity of Ada-specific or Modula-specific manufacture tools
is that they can deduce these two kinds of dependencies automatically.
The need to find all the appropriate object files to link is a special case
of the general problem of
processing all files of certain characteristics from all subsystems as a
group. Other examples from my past projects
- Pass all run-time symbol tables for IDL-based data structures
to a tool that gives each a unique structure number.
- Combine error descriptions from all subsystems to the
error sorting
tool to form a single database of all error messages.
A solution to this problem seems to require two mechanisms:
- Abstractions need the ability to add dependencies to a parameter or
global object. For example, the IDL translator abstraction could add
each structure symbol table to an "all IDL symbol tables"
object.
- There should be some means for turning a set of dependencies into
input for a tool.
The first two sections, on original requirements and
problem analysis, are the system requirements to
analyze. The three main steps are identifying the primary
concepts, identifying actors and use cases, and
representing the analysis of this information as a conceptual model.
A common first step in analysing requirements is to look for
frequently-occurring words or phrases (shown in italics in the
following).
The main concepts expressed in these requirements are:
- The system or project to build or rebuild
- Its components and subsystems (if any), some of which may
have independent development schedules.
- Objects, of which files and modules written in
specific languages are important special cases. They may exist
in multiple versions because developers change
them. Documentation, code, and chapters of books
can all be objects.
- Processing steps, which take some objects as inputs and
generate others as outputs, using particular tools
the builder must invoke
- Tools can be can be arbitrary, that is, unrestricted,
programs and commands, and can report errors as
they run.
Some, such a linkers, implicitly require a large collection of
inputs.
- Dependencies between objects and steps, including those that are
hidden in the typical usage of
make, such as
command-line options. Some dependencies are implied by
language rules, such as #include in C, or subclassing in
C++ or Java.
- Source objects, defined as those that are not the output of any
tool; they need to be archived to reproduce a given version of
the system.
- Libraries of objects; in the case of system libraries of
relocatable object code, these
generated objects must sometimes be thought of as source files, since
the only way to preserve them from changes is to archive them.
- Abstractions the developers use to think about complex system
building.
These requirements suggest four main roles (actors in UML-speak), and
one that combines two others. As
usually, one person might perform some or all of these roles.
- System modellers develop descriptions of systems for the build
tool, such as adding descriptions of new tools.
- Developers add new source files, modify old ones, and build or
rebuild software from original or changed source.
- Archivists save complete versions of the system to safe
storage, in order to release a system or save versions for future
maintenance.
- Installers obtain and rebuild stable versions of the system.
- Maintainer combine the installer and developer roles: retrieving
and building older software versions to reproduce bugs and fix them.
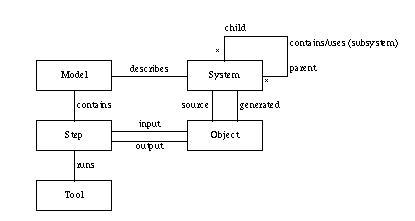
The diagram is incomplete; it needs to show tools, files, and strings as
subclasses of object. Objects also need "types" such as programming language
source file, relocatable object file, and so on.
At this stage of development we augment the classes of the conceptual model with additional implementation-specific
classes, assign responsibilities to specific classes, and identify
collaborations among the classes.
In this work, I assume the basic software manufacture tool follows
Borison's model. The key aspects of this model are as follows:
- The tool works from a manufacture graph, which is a directed acyclic
graph (DAG).
Such graphs have two kinds of nodes: processing nodes, where
work takes place, and object nodes, which are the inputs to and
outputs from processing steps.
- An important difference between such a graph and the dependency graphs of
programs like make is that a manufacture graph must represent
all dependencies, including not only the input files for a tool,
but the tool itself and any "hidden" files it references.
- For reproducibility, object must be considered immutable. The
operation of changing a source file and recompiling must be considered
to be substituting a new object for an old one in the manufacture
graph; the old one must still somehow be available.
- Thus the system builder must interface with a version control system
for source objects, and may need to manage a cache of its own generated
objects.
For concreteness we suggest a particular way of encoding relations
as an incremental change in the current make
input language.
The following table
defines the operations permitted in such expressions.
If several such definitions occur, the relation is their union;
this permits a form of distributed specification of a relation.
| Operation | Infix | Postfix
|
|---|
| ; | composition
|
| ! | | inverse
|
| + | union | transitive closure
|
| - | set difference
|
| * | intersection | reflexive transitive closure
|
| ( ) | parentheses (grouping)
|
One specifies when to rebuild a generated file by naming the relation that
governs generation.
output_file (expression):
command ....
means that, whenever any file related to
output_file
by the given relational expression changes,
one executes the given command to rebuild the output file.
We permit only one such declaration per output file;
in future work we will investigate methods of disambiguating among
several of them.
Certain dependencies are common enough to require some form of rule.
Thus we allow
&.c :(c_derives) &.o
to mean that any file with type
.c
has relation
c_derives
to a file of the name name with type
.o.
This is similar to the metarules of the mk[mk]
program; however, we allow naming several separate dependencies, while
mk allows more complex name pattern matching.
Any set of files corresponds to an identity relation.
The expression
(rel!);rel
defines an identity relation for the range of
rel;
similarly,
rel;(rel!)
corresponds to the domain.
Certain useful sets correspond to such domains and ranges;
we introduce
dom(relation)
and
rng(relation)
to represent them.
The set of all object modules generated by the C compiler is thus
rng(c_derives).
Composing a relation with a set means restricting the domain or range
of the relation; thus
rel;set
is the subset of
rel
with range restricted to
set.
We can say
{file1,file2,...,fileN}
to explicitly construct a set of N named files.
Tools may need to process lists of files obtained from relations;
we thus give a way to generate a string from a set or relation.
The expression
@[relation]
constructs a string consisting of the names of all the files in the
domain and range of the relation,
separated by spaces.
@[option relation]
gives a sequence of files in a topological sort of
relation;
if file A is related to file B, then
the < (>) option requires that A appear before (after) B in the result string.
@[option relation[file]]
gives a topological sort of the named relation starting with the given
file instead of with the natural roots of the relation.
@[relation[file]]
is the set of files related to the given file by the given relation;
it is a shorthand for
@[rng({file};relation)].
As topological sorting is related to transitive
closure,
@[option relation+]
gives the same results as
@[option relation].
The implementation requires augmenting the class diagram of the conceptual model with classes that give additional
detail (such as relational expressions), and which provide much of the
detailed processing.
Having run out of time, I omit the former and summarize the latter in the next
section.
The following figure
illustrates the basic subsystem of the
quilt prototype.
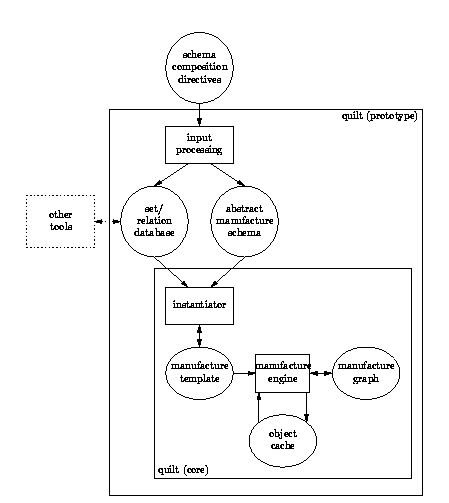
The core of
quilt
consists of:
- The set/relation database manages sets, such as "all C source
files", base relations (such as "file directly includes other file"),
and relational expressions (such as "directly or indirectly includes").
- The database may interact with other tools, especially to extract
language-specific base relations, like "includes" and "subclass of".
Other tools may also request lists of objects meeting certain criteria,
such as "all Java modules to be compiled before this one".
- The manufacture template,
conceptually similar to a
make input file (makefile),
describes how to generate objects from other objects,
and under what conditions to do so (such as: whenever there is a
change in some source object on which the generated object depends).
- The object cache
is the set of all objects generated under the direction of
the manufacture template.
- The manufacture graph
is an instantiation of the manufacture template, with
placeholders in the template replaced by references to particular
objects in the cache.
A fully instantiated graph (one with no placeholders remaining)
represents one complete version of a system.
- The manufacture engine
interprets the template and adds generated objects to the cache, while
updating the graph to represent the newly-generated objects.
- What distinguishes
quilt from other
make-like programs is the
instantiator, which constructs the manufacture template from
a database of user-definable relations among objects, and an
abstract manufacture schema, which describes how to decide what
steps are needed to produce certain kinds of output from available
inputs (a cousin to the implicit rules used in make).
If one changes some source objects, the engine builds a new
manufacture graph to represent the changed system. Objects from the
old system might remain in the cache, depending on the engine's
cache control policy, so that reverting to older versions of some
source files might not require generating new objects, but merely
changing the manufacture graph.
- Ellen Borison, "A Model of Software Manufacture," in
Reidar Conradi, Proceedings of the International Workshop on
Advanced Programming Environments, pages 197-200, Springer-Verlag
(1986). Lecture Notes In Computer Science 244.
- Andrew Hume.
Mk: a successor to make
Proceedings of the Summer 1987 USENIX Conference,
pages 445-457, 1987
- David Alex Lamb,
"Relations In Software Manufacture"
Queen's University Department of
Computing and Information Science
Technical Report 1990-292
(postscript; 73.261 Kbytes)
- David Alex Lamb, "Abstraction Problems in Software Manufacture."
Queen's University Department of
Computing and Information Science
Technical Report 1989-243
(postscript; 58.211 Kbytes)
February 1989. 7 pages.
- Peter Miller.
Recursive
Make Considered Harmful