|
ELEC
372
|
The maintenance task given was to change the list representation strategy from arrays (as given) to linked lists. As it happens, the given application's architecture gives a strong hint on how to proceed. The array strategy is almost invisible outside the base class ListImpl. For this reason, by far the easiest kind of solution is to replace the internals of ListImpl with a linked-list version. The definitions of the subclasses CourseListImpl and StudentListImpl can remain almost unchanged. If the change is carried out correctly, the rest of the application remains unchanged, too.
The linked list implementation requires a new class (I called it Node) to represent nodes of a linked list. It is very simple, because its only purpose is to be a target for Java's dynamic memory allocation, which is only available through new expressions (and therefore requires a class definition).
Your submission is given a mark out ot 100, which will be reduced to a mark out of 10 when it contributes to the marking scheme.
The disadvantage of this interface technique is that object creation is more complicated. In Java, a new instance of Class is created by evaluating new Class. There is no other way to create a new instance. But an interface cannot be instantiated using new because interfaces are 'abstract', that is, they are a view of classes, not a kind of class in their own right. What this means is that either
The principal advantage of the linked-list strategy is that it allows memory allocation to be more flexible: if there are many lists, each only occupies as much as necessary; and if a list needs to be very large, then only the memory available to the Java engine limits it. By contrast, the array strategy requires a fixed amount of space per list, as much as the maximum required: if most lists are much smaller than the maximum, this is inefficient use of space.
On the other hand, retrieval from a linked list, by element number,
requires traversal from the beginning of the list, whereas retrieval from
the array requires only indexing. If there are many retrievals from
long lists then the added time will be noticeable for the linked-list strategy.
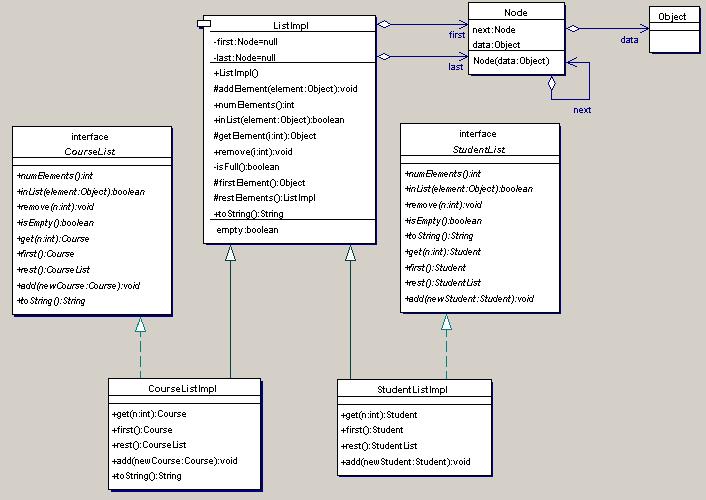
UML Diagram This part of the lab was poorly done. Very few people seemed to understand the relationship between their code and the UML. In fact several people turned in the same diagram that was supplied with the lab. If you are showing attributes in the class box then showing role names as labels on associations is optional. However it is an error to supply an erroneous name. Many people correctly added a Node class while removing the original object class, however they left the original role name and multiplicity (elements 0..*) on the Node link. The purpose of UML is to reveal the structure of a design or implementation.
Discussion Some people stated that a linked list was always more efficient with respect to memory use. However they failed to realize that each node in a linked list stores one or possibly 2 pointers to other nodes (if you define an inner class, that is, a class defined and used locally in a scope, and then you refer to the outer class members from within the inner class, you pay at least one more pointer). There were various incorrect statements about the complexity of various operations:
Insertion: Adding a new element to the end of a singly linked list is O(n), for a doubly linked list it is O(1). Searching vs lookup: A linear search for either an array or a linked lists is O(n), wheras a lookup based on an index is O(1) for an array and O(n) for a linked list. Deletion: Removing an element from an array (the lab's implementation) is O(n) because you have to reorganize the array. Removing an element from a linked list is O(n) because you have to traverse the list to find the element to be removed.
Testing In addition to the test cases supplied with the lab
and mentioned above you could also test for:
undergraduate with a thesis postgraduate enrolled in courses mangled inputs, by this I mean incorrectly formatted text from the input file
Code The isFull() method is interesting. The easiest
thing to do was to leave there but change it to just return null, meaning
the linked list is never full. It is also permissable to remove it
completely since it was a private method (and therefore not part of the
interface). Had this method been a part of the interface then it
is obligatory to supply it in order not to 'break' the interface.
Lots of solutions were basically right operationally, but completely failed to explain what they were doing. In particular, when a linked list is represented with one "extra" node to make traversal easier, it definitely requires a comment. In fact, for any abstract data type there should be a block of comments at the beginning clearly laying ouf how the abstract type (identified with the public operations' behaviour) is represented internally by data structures. This necessity was almost universally ignored.
If you are going to use meaningful names such as next or head then do so. However it is better to use some totally cryptic name rather than a misleading one. For example if you have a reference to a single element call it element not elements. If you have a class that is a Node then call it a Node, Item, Element, etc. Do not call it a Fred or LinkedListImpl, that's not what it is.
This diagram was made by one of the TAs, Brad Graham. Note that the roles played by Node and Object are shown clearly, and the cardinality is indicated diagramatically using open-diamonds and arrows, in UML style.